
Ray란?
- 버클리 대학 RISE 연구실에서 만들었다
- 분산 어플리케이션을 만들기 위해 단순하고 범용적인 API를 제공하는 라이브러리
- 확장 가능한 고성능 분산/병렬 머신러닝 프레임워크
- 다수의 분산 머신러닝 라이브러리를 보강한다
- 최소화한 구문 때문에 기존 앱의 많은 부분을 재작업하지 않고도 병렬화가 가능하다. 기존의 코드 변경을 하지 않고 기존의 순차 코드 베이스에서 몇줄의 코드만 추가하여 병렬 처리를 쉽게할 수 있다.
- 필요에 따라 로컬 하드웨어, 주요 클라우드 컴퓨팅 플랫폼에서 자동으로 노드를 가동할 수 있는 자체 클러스터 관리자도 내장돼 있다.
Ray 서밋 내용:
- Ray로 게놈 데이터 분석하기 프로젝트
- 빅데이터 로딩 & 전처리하는 기능이 있다.
- MLSQL, Spark, Ray 같이 사용하는 방법이 있다 (빅데이터 & AI)
Ray의 분산/병렬 시스템 Ray Core의 장점:
- 다수의 컴퓨터에서 동일한 코드를 실행시킬 수 있다.
- State of the Art하고 통신 가능한 Microservice 및 Actor를 구축할 수 있다.
- 기계 고장 및 시스템 고장을 훌륭하게 처리할 수 있다.
- 거대한 데이터와 수치 데이터를 효율적으로 처리할 수 있다.
Ray의 성능:
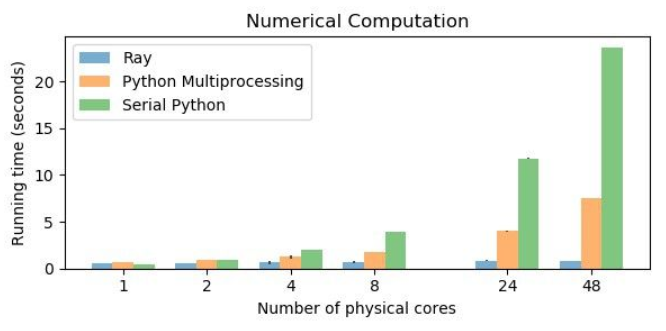
벤치마크 결과에 따르면 Core의 수가 증가함에 따라서 압도적으로 성능이 향상하는 것을 볼 수 있다. 이 성능 차이는 프로세스간의 객체 전달을 위한 과정에서 발생한다. 또한 48물리 코어를 가지는 환경에서 Ray가 Multiprocessing보다 9배 빠르고, 싱글스레드 환경보다 28배 빠르다.
Python Multiprocessing:
- 큰 데이터를 다른 프로세스에 전달할때... pickle사용 → 직렬화 → 전달
- 단점: 모든 프로세스가 데이터에 대한 복사본을 만들어야 한다 → 큰 메모리를 할당한다 → 역직렬화에서 발생하는 큰 오버헤드를 가질 수 밖에 없다.
Ray:
Python Multiprocessing의 문제를 해결하기 위해… 직렬화 오버헤드가 적은 Apache Arrow를 사용한다 → Zero-Copy 직렬화를 수행한다 → 직렬화된 데이터를 In-Memory Object Store인 Plasma를 이용하여 빠르게 공유한다.
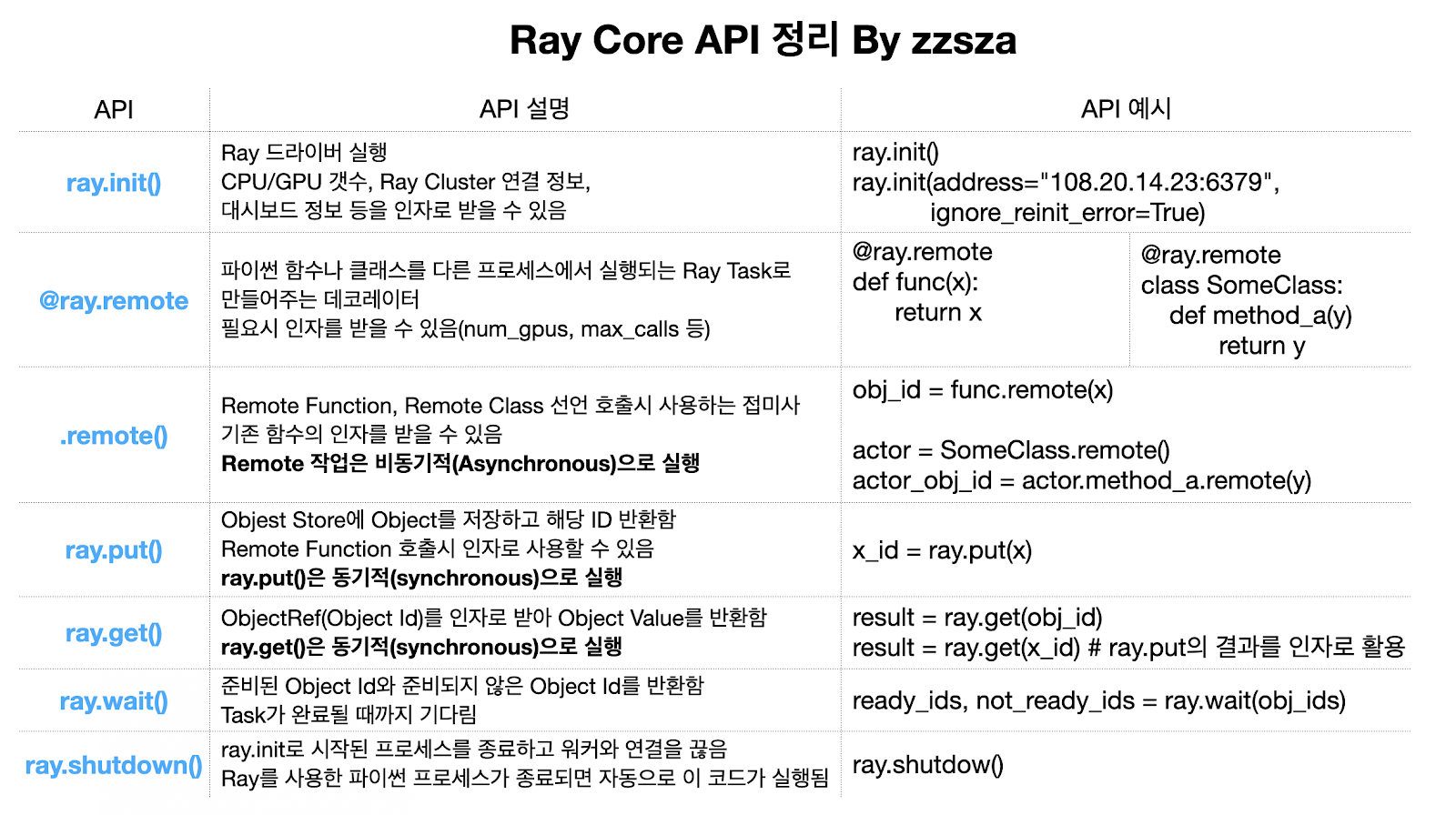
Ray Core API 정리:
'IT' 카테고리의 다른 글
| UI path와 Brity RPA 비교 (0) | 2024.06.07 |
|---|---|
| RPA(Robotic Process Automation) (0) | 2024.05.16 |
| [성장하는 데이터 분석가에게 필요한 3가지 마인드셋] (0) | 2023.01.02 |
| 2022 연구실 안전교육 스킵하기 (0) | 2022.11.30 |
| filebrowser로 웹에서 파일 폴더 공유하기 (0) | 2022.09.27 |