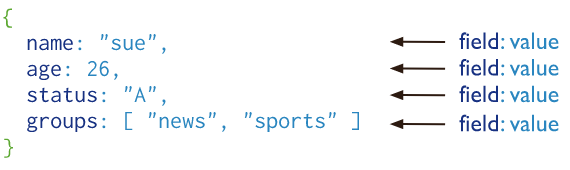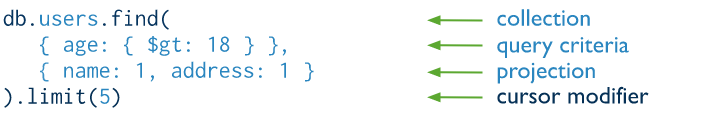(1/10) 문제 이해하는데도 오래걸려서 포기하려고 했던 문제,, 2번 정도 보고 완벽히 아니고 대충 이해가 갔다!
(1/11) 이해 완료~
- 코드:
정답 코드 중에 파이썬이 없어서 자바코드로 먼저 이해했다.
<코드 이해 돕기 위한 설명>
100 200 300으로 정렬한 뒤에 1번 퀘스트를 진행하면 경험치에서 100을 빼주고, 1번을 진행한 상태니까 100을 어딘가에 한번 더해줄 수 있다.(활성화 된 스톤이 1개니까) 그다음 2번 퀘스트를 진행하면 경험치에서 200을 빼주고, 200만큼을 어딘가에 두번 더해줄 수 있다. (활성화 된 스톤이 2개니까) 이제 3번 퀘스트를 진행하면 경험치를 빼줄 필요 없이 300을 어딘가에 두번 더해주면 된다.
< 내가 이해한 코드와 문제 설명>
"예를 들어서 2,3 번째 아케인스톤이 활성화되어있고(2개가 활성화 되어있네! 그럼 해당 퀘스트를 제외하고 다른 아케인스톤에 해당 퀘스트의 경험치를 2번 뿌릴 수 있음) 첫번째 퀘스트를 진행했을 경우, 첫번째 아케인스톤을 획득하고 2,3번째 아케인스톤에 첫번째 퀘스트의 경험치가 쌓이고 첫번째 아케인스톤 경험치는 0이 된다."
즉, 진행한 퀘스트에 따른 아케인스톤 경험치가 0이 되므로 감소되는 경험치를 최소화하기 위해서는 오름차순으로 정렬해주는 것이 맞다. 퀘스트별 아케인스톤 경험치는 다른 아케인스톤에 본인 경험치를 줄 수가 있는데 활성화 개수에 따라 몇번 줄 수 있는지 달라진다. 그리고 경험치를 주면 본인이 가지고 있던 경험치는 0이 되게한다.
import java.util.Arrays;
import java.util.Scanner;
public class TemplateA {
public static void main(String[] args){
Scanner scan = new Scanner(System.in);
int quest = scan.nextInt();
int activeS = scan.nextInt();
int [] arr = new int [quest];
for(int i = 0; i < quest; i++) {
arr[i] = scan.nextInt();
}
Arrays.sort(arr);
//오름차순으로 정렬해주어 최대 아케인스톤이 활성화 전까지
//감소되는 경험치를 최소화한다.
int count = 0;
//count는 최대 활성 아케인스톤 값까지 증가할 변수
int exp = 0;
//최대 경험치가 들어갈 변수
for(int i = 0; i < quest; i++) {
if(count < activeS) {
count ++;
//최대 아케인 스톤값이 될때까지 하나씩 더해줌
exp -= arr[i];
//최대 아케인 스톤 값이 되기 전까지는 하나의 경험치가 사라지게
//됨으로 그 아케인 스톤의 경험치를 총경험치에서 빼줌
}
exp += (arr[i] * count);
//이후 활성화된 아케인 스톤의 수와 경험치를 곱해줌
}
System.out.println(exp);
}
}
- 코드 이해 후 파이썬으로 구현
n, act = map(int, input().split())
k = list(map(int, input().split()))
k.sort() # 감소되는 경험치 최소화
cnt, exp = 0, 0
for i in range(n):
if cnt< act:
cnt+=1
exp -= k[i]
exp += k[i] * cnt
print(exp)
t = int(input())
num = 0
for _ in range(t):
k = int(input())
n = int(input())
k0 = [x for x in range(1,n+1)]
for a in range(k):
for b in range(1,n):
k0[b] += k0[b-1]
print(k0[-1])
1. 큰 문제를 작은 문제로 나눌 수 있을 때 - 크고 어려운 문제가 있으면 그것을 먼저 잘게 나누어서 해결한 뒤 처리
-> 이 과정에서 메모이제이션(memoization) 사용해야함: 이미 계산한 결과를 배열에 저장
2. 작은 문제로부터 구한 결괏값을 큰 문제에서도 활용 가능
2가지 문제 풀이 방식
1. 상향식(바텀 업) 방식: 가장 작은 문제의 답부터 찾아가는 방식, 반복문 사용
2. 하향식(탑 다운) 방식: 가장 큰 문제부터 시작하여 작은 문제 순으로 답을 찾아가는 방식, 재귀 함수 활용
1. 상향식(바텀 업) 방식
# 계산된 결과를 memoization 하기 위해 리스트 초기화
d = [0] * 100
d[0] = 1 # a_1 = 1
d[1] = 1 # a_2 = 1
# 바텀 업 방식: 반복문 활용
for i in range(3, n+1):
d[i] = d[i-1] + d[i-2]
n = 99
print("fibo({}): {}".format(n, fibo(n)))
2. 하향식(탑 다운) 방식
# 계산된 결과를 memoization 하기 위해 리스트 초기화
d = [0] * 100
# 탑 다운 다이나믹 프로그래밍 기법과 재귀 함수를 활용한 피보나치 수열 구현
def fibo (x):
# 종료 조건 (전달인자가 1 또는 2일 때 1을 반환)
if x == 1 or x == 2:
return 1
# 계산된 결괏값이 존재할 경우 해당 결과값 반환
if d[x] != 0:
return d[x]
# 계산된 결괏값이 존재하지 않을 경우 피보나치 수열의 결과를 반환
d[x] = fibo(x-1) + fibo(x-2)
return d[x]
n = 99
print("fibo({}): {}".format(n, fibo(n)))
- 코드: DP문제는 처음이라,, 되는 확률들의 횟수를 다 따로 저장해서 비교하는 방식으로 해야한다. 머릿속으로는 생각했는데 어떻게 해야할지 아예 감이 안잡혔다ㅠㅠ 상향식 하향식 방식이 있는데 상향식이 더 코드는 이해하기 쉬웠다. DP 알고리즘에 대해서 따로 정리하기!
n = int(input())
cnt = 0
while n>0:
if n%3==0:
n = n//3
cnt+=1
if n==1:
break
if n%2==0:
n = n//2
cnt+=1
if n%2==0:
n = n//2
cnt+=1
if n==1:
break
if n%3==0:
n = n//3
cnt+=1
n = n-1
cnt +=1
print(cnt)
- 정답 코드:
n = int(input())
d = [0] * (n + 1) ## d에 계산된 값을 저장해둔다. n + 1이라고 한 이유는, 1번째 수는 사실 d[1]이 아니고 d[2]이기 때문에, 계산하기 편하게 d[1]을 1번째 인 것 처럼 만들어준다.
print(d)
for i in range(2, n + 1): #11
## 여기서 왜 if 1빼는 방법, 2 나누기, 3 나누기 동등하게 하지 않고 처음에 1을 빼고 시작하는지 의아해 할 수 있다.
## 1을 빼고 시작하는 이유는 다음에 계산할 나누기가 1을 뺀 값보다 작거나 큼에 따라 어차피 교체되기 때문이다.
## 즉 셋 다 시도하는 방법이 맞다.
## 여기서 if elif else를 사용하면 안된다. if만 이용해야 세 연산을 다 거칠 수 있다, 가끔 if continue, else continue를 쓰는 분도 계신데, 난 이게 편한듯.
d[i] = d[i - 1] + 1
print(d[i])
if i % 3 == 0:
d[i] = min(d[i], d[i // 3] + 1) ## 1을 더하는 것은 d는 결과가 아닌 계산한 횟수를 저장하는 것 이기 때문이다. d[i]에는 더하지 않는 이유는 이미 1을 뺄 때 1을 더해준 이력이 있기 때문이다.
print(d)
if i % 2 == 0:
d[i] = min(d[i], d[i // 2] + 1)
print(d)
print(d[n])
-> 일단 dfs/bfs의 개념부터 알아가느라 정답을 먼저 보고 고민을 해봤다. 문제는 이해가 갔는데 정답 코드를 봐도 왜 저렇게 배열을 만드는지 이해가 안간다.. (12.28) -> 이해 완료!
import pandas as pd
import sys
n = int(input())
tree = [[] for _ in range(n+1)] # 빈 배열 생성
parent = [-1]*(n+1)
for _ in range(n-1):
a, b = map(int, input().split())
tree[a].append(b)
tree[b].append(a)
def dfs(n):
for i in tree[n]:
if parent[i] == -1:
parent[i] = n
dfs(i)
dfs(1)
for i in range(2, n+1):
print(parent[i])
--> tree의 배열을 보면 이런식으로 결과가 나오는데 각 노드 순서별로 어떤 노드와 연결되어있는지 나타내는 배열이다!
예) 0번 노드는 공백, 1번 노드와 연결된 노드는 4,6, 2번 노드와 연결된 노드는 2, 3번 노드와 연결된 노드는 5,6
mongoDB는스키마를 고정하지 않은 형태(Schema-less 구조)입니다.이러한 특징으로 필드 추가 및 제거가 간편합니다.
분산 확장이 간단합니다.
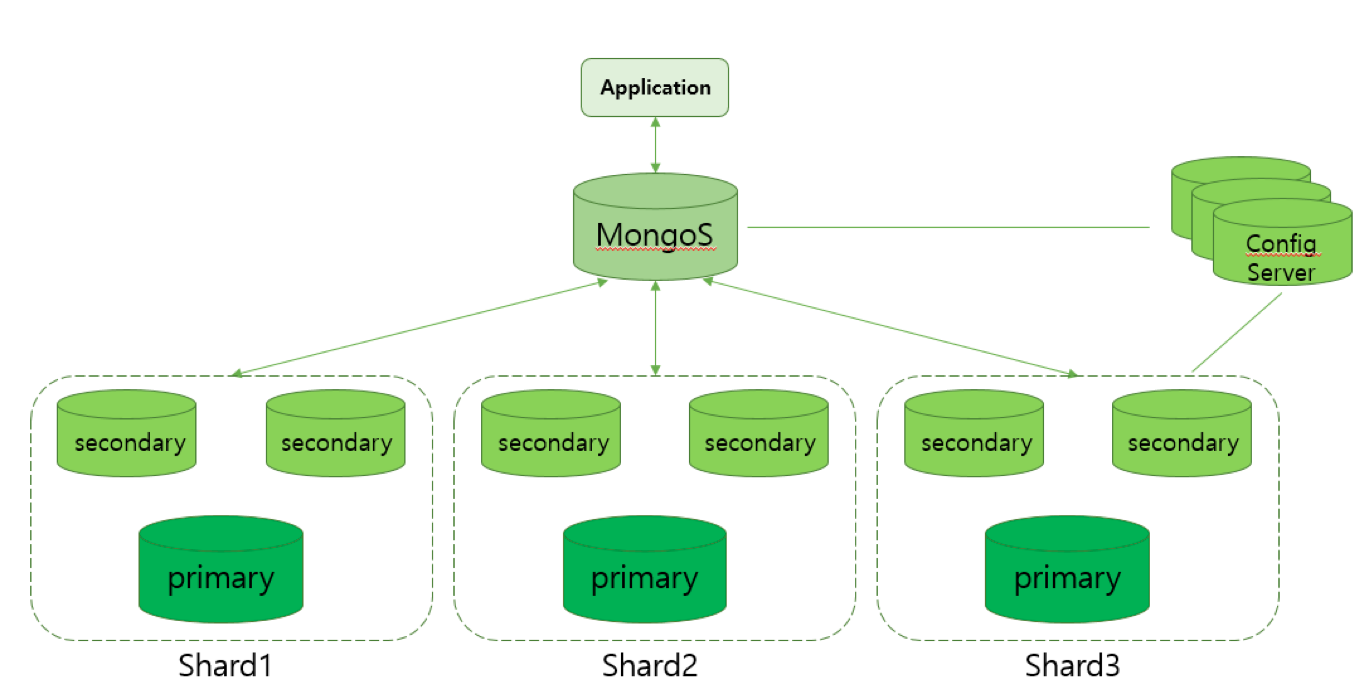
아래의 그림과 같이샤딩 시스템(샤딩 : 샤드(분산하는 각각의 장비)에 걸쳐 있는 데이터를 분할하는 처리)을 이용하면 분산 확장이 간단합니다.
Mongo DB sharding
2. mongoDB 개념
mongoDB에서는 JSON, BSON 타입 모두 사용합니다. BSON 타입이 무엇인지 어디서 사용되는 건지 알아봅시다. 더 자세한 내용을 확인하고 싶으면mongoDB 사이트에서 확인해 주세요.
2-1. JSON 타입과 BSON 타입
JSON 타입
mongoDB는 Document 형태로 데이터를 저장합니다. 이러한 표현 방법을 java script 형식의 오브젝트 표기법 즉, JSON 타입이라고 말합니다. 이 데이터 타입은 사람이 읽고 쓰기 쉽고, 기계가 파싱하고 생성하기 쉽다는 장점이 있습니다.
BSON 타입
mongoDB에서는 모든 데이터는 반드시 JSON 타입으로 표현됩니다. 하지만, 데이터베이스 내에서 저장될 때는 BSON 타입의 바이너리 형태의 데이터로 반환되어 저장합니다.
BSON 타입은 Binary JSON의 약어로, JSON 문서를 바이너리로 인코딩한 포맷이다. JSON과 비교하여 BSON은 스토리지 공간과 스캔 속도 모두에서 효율적으로 설계되어 있다는 장점이 있습니다.
2-2. mongoDB 용어 설명
mongoDB에서 사용하는 용어에 대해 알아봅시다. 이를 쉽게 이해하기 위해 RDBMS 용어와 비교해 봅시다. 아래 표와 같이 mongoDB에서는 table를 collection(컬렉션)이라 하고, row(행)을 Document(도큐먼트), db server를 mongod, db client를 mongo라고 부릅니다.
RDBMS
Mongo DB
Database
Database
Table
Collection
Row
Document
Index
Index
DB server
Mongod
DB client
mongo
3. 기본 쿼리
이제 mongoDB 기본적으로 사용되는 CRUD 쿼리에 대해 살펴보도록 하겠습니다. 아래 자료는mongoDB documentation를 참고하였습니다.
3-1. C(Create) - insert
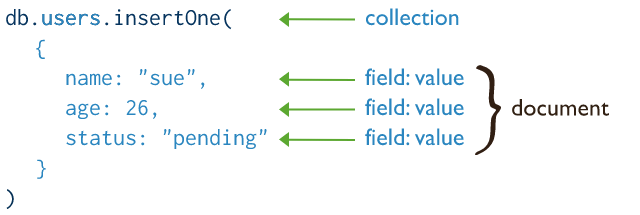
insert 명령어를 이용하여 json 형식 데이터를 삽입합니다. 아래 그림과 같이 field:value 형식으로 되어있는 것을 확인할 수 있습니다.
Query를 더욱 효율적으로 할 수 있도록 documents에 기준(key)을 정해 정렬된 목록을 생성하는 것입니다. 인덱스가 없다면, Mongo DB는 full collection scan(collection의 데이터를 처음부터 끝까지 하나하나 조회) 방식으로 스캔하게 됩니다.Hash index를 제외하고 Mongo DB는 B-Tree 구조로 Indexing으로 되어 있습니다.
4-2. 기본 Index
모든 Mongo DB의 컬렉션은기본적으로 _id 필드에 인덱스가 존재합니다.
컬렉션 생성 시 _id 필드를 따로 지정하지 않으면 mongod 드라이버가 자동으로 _id 필드 값을 ObjectId로 설정됩니다.
_id 인덱스는 unique 하고 이는 MongoDB client가 같은 _id를 가진 문서를 중복적으로 추가하는 것을 방지합니다.
4-3. Index 생성, 조회, 제거하기
생성하기
createIndex() 메소드 사용하여 생성합니다. 값을 1로 하면 오름차순, -1로 하면 내림차순 정렬됩니다.
> db.collection.createIndex( { key: 1 } )
조회하기
> db.COLLECTION.getIndexes()
제거하기
> db.COLLECTION.dropIndex( { KEY: 1 } )
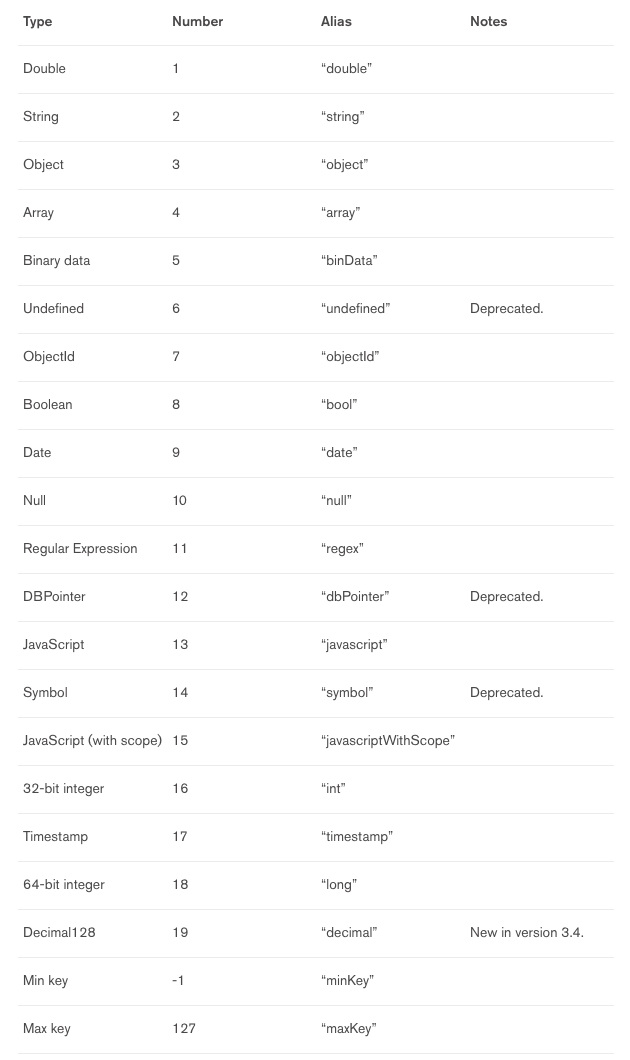
5. data type
mongodb data type은 아래 사진과 같이 여러 타입이 존재합니다. 많이 사용되는 데이터 타입만 확인하고 넘어가겠습니다.
ObjectId: 12 bytes로 구성된 하나의 document에 유일한 ObjectId가 자동으로 부여됩니다.
String: 문자열로 어떠한 UTF-8 문자열도 표현 가능합니다.
Date: UNIX 시간 형식으로 저장됩니다. 새로운 Date 객체를 생성할 때는 항상 Date가 아닌 new Date 호출, Date 호출 시 날짜 객체가 아닌 날짜의 문자열 표현 반환합니다.
빅데이터를 저장하기 위해서는 한 대의 서버에 저장하는 것은 불가능합니다. 초당 엄청난 양의 데이터를 insert 하면 Write scaling 문제가 발생하여 서비스 성능 저하를 유발합니다. 따라서 이를 해결하기 위해여러 대의 서버에 분산 처리하는 것이 이상적입니다.
샤딩을 하게 되면 여러 대의 독립된 프로세스가 병렬로 작업을 동시에 수행하여 이상적으로 빠른 처리 성능을 보장받습니다. 또 하나의 서버에서 관리를 하면 유실 시 큰 손실이 따르게 됩니다. 분산 처리를 하면 이러한 위험 요소로부터 안전하게 데이터를 저장, 관리할 수 있습니다.
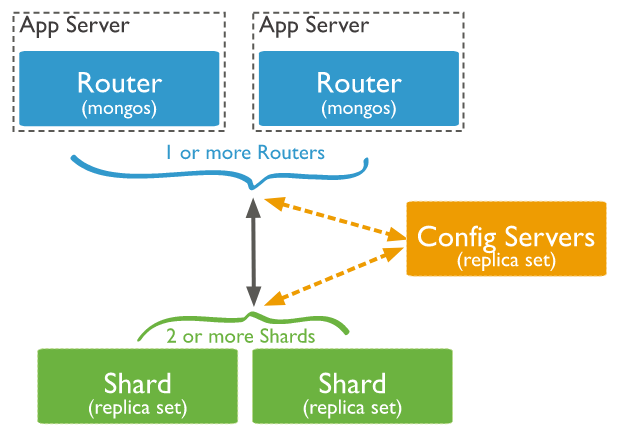
6-2. 샤딩 시스템 구조
샤딩 시스템 구조
mongos 라우터
mongos 프로세스는 중계자 계층으로 응용 계층(client)에서 전달된 질의를 분석하여 적절한 샤드에 보내는 라우터 역할을 합니다. 또한 mongos는 각 서버에서 어떤 일을 하는지 client가 모르게 해주는 역할을 합니다.
shard
Shard는 데이터를 하나 혹은 그 이상의 샤드에 걸쳐 분산 저장한다. 각 샤드는 전체 데이터의 일부를 저장한다. 그리고 각 샤드는 그림과 같이 리플리카 셋으로 구성되어 있습니다.
config servers
config servers는 샤드 시스템에 대한 설정 세팅과 메타 데이터를 저장/관리합니다. 다시 말하면 config servs는 각 샤드 서버에 어떤 데이터가 어떤 식으로 분산 저장되어 있는지에 대한 meta 데이터가 저장되어 있습니다. mongoDB 3.4에서는 config servers도 리플리카셋으로 구성되어야 한다고 합니다.
6-3. shard key 구성
shard key 구성 방법은mongoDB 샤딩 시스템 구축할 때 가장 중요합니다. 이는 여러 개의 샤드 서버로 분할될 기준 필드를 가리키며, partition과 load balancing에 기준이 됩니다.따라서 적절한 카디널리티를 가진 필드가 shard key로 선택되어야 합니다.
카디널리티는 조건을 만족하는 데이터의 분산 정도를 나타내는 값으로 전체 데이터 중에서 조건을 만족하는 데이터의 분포가 넓으면 낮은 카디널리티라고 하며 분포가 좁으면 높은 카디널리티라고 표현합니다. 예를 들어 사원번호는 고유한 값이니 높은 카디널리티입니다. 남/여 라는 필드로 샤드키를 구성하면 낮은 카디널리티입니다.
결과적으로 카디널리티가 너무 높거나 낮은 필드는 shard key로는 적절하지 않습니다. 왜냐면 데이터를 적절하게 분산 저장하기에는 데이터 값의 유형이 적절하게 잘 분포되어야 할 필요가 있습니다.
7. replication
복제는여러 서버에서 데이터베이스 서버를 분산하고 관리하는 것입니다."장애는 항상 발생한다"라고 하는 피할 수 없는 사실 때문에 대부분의 데이터베이스 관리 시스템에서 복제는 핵심적 요소입니다. mongoDB에서 복제는 아래와 같은 특징을 가집니다.
Master/slave 관계를 갖는 원본과 복사본 사이입니다.
Master에서 쓰기 operation을 수행하고 이러한 operation을 Master의 oplog(명령어 기록)에 기록합니다. slave는 Master의 oplog를 복제하고 각자의 데이터 세트에 오퍼레이션을 비동기 방식으로 동일하게 적용됩니다.
Master는 (read/write)용이고, slave는 master의 데이터를 미러링하고 있는 read 전용입니다. Slave에 write가 가능하도록 설정해 줄 수 있지만 속도면에서 권장하지 않습니다.
7-1. 복제 동작 원리
mongoDB에서 복제가 되는 순서는 아래와 같습니다.
몽고디비 슬레이브는 주기적으로 마스터에게 자신의 optime보다 큰 oplog 요청합니다.
oplog에는 primary가 데이터가 아닌 명령어를 기록합니다.
5초 안에 마스터에서 쓰기 연산이 발생하면 데이터를 응답합니다. 만약 발생하지 않았다면 데이터가 존재하지 않다는 응답을 보내줍니다.
슬레이브는 요구한 oplog 데이터가 존재하면 자신의 oplog에 데이터를 저장하고 바로 마스터에게 다시 oplog를 요청합니다.
7-2. 리플리카셋(replicatset)
마스터 서버와 슬레이브 서버의 관계는 원본 데이터베이스에 대한 복제한 데이터를 하나 더 저장하는 관계를 의미합니다. 장애가 발생하면 복구 작업으로 작업을 수행할 수 있습니다. 그러나 실시간으로 마스터 서버에 복구는 어려우며 슬레이브 서버를 바로 사용하기에도 어렵습니다. 따라서 이런 문제점을 개선한 것이 리플리카셋 입니다.
리플리카셋 특징
리플라카셋 특징은 아래와 같습니다.
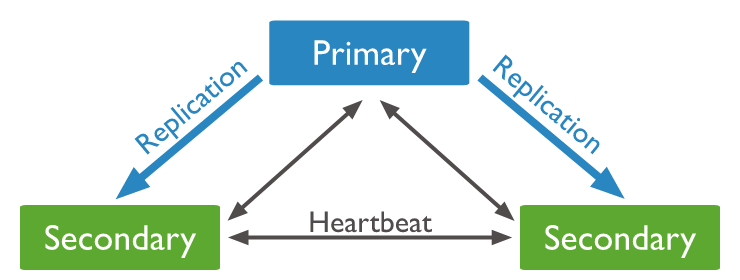
primary 서버는 2초 단위로 secondary 서버 상태를 체크하며 동기화를 위한 heartbeat 작업을 수행합니다.
만약 secondary 서버가 중지되더라도 복제 작업만 중지될 뿐 primary 서버에 대한 읽기 작업은 정상적으로 수행합니다.
secondary 서버가 복구되면 그동안 밀린 데이터를 복구하기 위해 primary 서버는 계속 oplog를 저장하며, 복구되면 자동으로 동기화해줍니다.
만약 primary 서버가 장애가 생긴다면 secondary 서버를 primary 서버로 만들게 됩니다.
리플리카셋 동작 원리
client의 요청을 처리하는 하나의 primary server와 primary server의 복제 데이터를 가진 여러 secondary server로 구성됩니다. 이 서버들은 서로 heartbeat로 서로 죽었는지 주기적으로 확인합니다.primary 서버는 heartbeat가 과반수를 가져야 하며, 그렇지 않은 경우 seconday 서버로 전환되고 primary 서버를 뽑기 위해 투표를 시행합니다. primary가 되기 위한 조건은 priority(master가 되는 우선순위)와 votes 등이 있습니다.
리프리카셋
8. 마무리
이번 시간에는 mongoDB에 대한 전체적 내용을 알아보았습니다. 각 주제별 자세한 내용을 다루지는 않았지만 mongoDB에 대한 전체적인 개념을 파악하는데 초점을 두었습니다. 각 주제에 자세한 내용은 다음에 블로그에 포스트하도록 하겠습니다! 😃
yo = int(input())
_list = []
for i in range(yo):
_list.append(int(input()))
_list = sorted(_list, reverse=True)
for a in _list:
print(a, end=' ')
std = int(input())
std_inf = []
for i in range(std):
std_inf.append(input().split(' '))
# std_inf = [['ㅎ', 95],['ㅇ','77']]
for i in range(len(std_inf)):
std_inf[i][1] = int(std_inf[i][1])
sort = sorted(std_inf)
for i in range(len(sort)):
print(sort[i][0], end=' ')
n = int(input())
move = map(str, input().split(" "))
# n = 5
# move = ["R", "R", "R", "U", "D", "D"]
ga, se = 1, 1
for i in move:
if i == "R":
if ga == n:
pass
else:
ga += 1
elif i == "U":
if se == 1:
pass
else:
se -= 1
elif i == "L":
if ga == 1:
pass
else:
ga -= 1
elif i == "D":
if se == n:
pass
else:
se += 1
print("%s %s" %(se, ga))