실버라인 DP 문제가 다 어려워서 브론즈 1 단계인 DP를 풀어보았다. 처음에 재귀함수를 시도했는데 실패하고 while 문을 써서 2수가 될때까지 돌아가게 설정했다.
a = input()
b = input()
arr = []
s = []
for i in range(8):
arr.append(a[i])
arr.append(b[i])
while len(arr) != 2:
for i in range(len(arr)-1): # 0~16
s.append(str((int(arr[i]) + int(arr[i+1]))%10))
arr = s
s = []
print(''.join(i for i in arr))
이 문제는 문제의 패턴을 찾으면 풀 수 있었다. 어떤 규칙성이 보이면 시간이 더 걸리더라도 패턴을 먼저 찾기 위해 노력하자.
1 -> 1개
2 -> 2개
3 -> 4개
4 -> 7개
5 -> 13개
6 -> 21개
7 -> 44개 순으로 되므로
점화식: (n>3) f(n) = f(n-1) + f(n-2) + f(n-3)
def sol(n):
if n == 1:
return 1
elif n == 2:
return 2
elif n == 3:
return 4
else:
return sol(n-1) + sol(n-2) + sol(n-3)
n = int(input())
for i in range(n):
a = int(input())
print(sol(a))
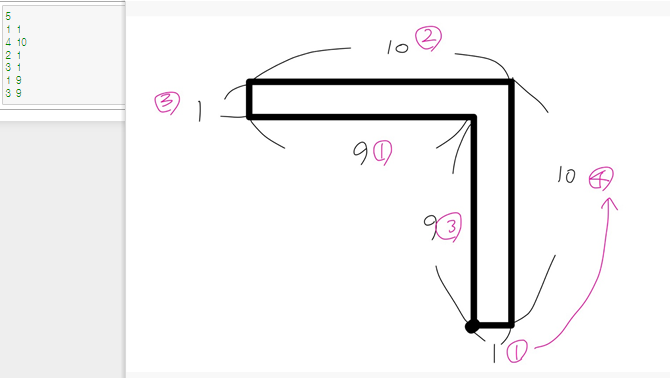
큰 전체 삼각형에서 작은 삼각형을 빼서 넓이를 구하는 것으로 생각했다. 처음엔 단순히 저 예제에만 적합한 코딩을 해서 애를 먹었다. 최소 최대로만 값을 구해서 계산했었는데 그렇게 풀면 아래와 같은 예제는 조건이 충족되지 않는다. 따라서 참외밭은 ㄱ자 모양이나 ㄴ자 모양, 출발 꼭지점의 시작점은 어디서든 가능, 반시계 방향으로 돎을 따져서 생각해야한다.
최대로 가장 긴 가로 세로에 붙어있는 양 옆의 변 길이를 구해서 빼는 방식으로 구현해보았다. 그런데 런타임 에러가 나서 확인해보니 %6을 붙여주면 에러가 나지 않았다. 인덱스가 6이상이면 에러가 날뿐만 아니라 시작점을 알 수 없는 상태니 6이내의 값으로 구해야하기 때문이다.
n = int(input())
bat = [list(map(int, input().split())) for _ in range(6)]
w = 0; w_idx = 0
l = 0; l_idx = 0
for i in range(len(bat)):
if bat[i][0] == 1 or bat[i][0] == 2:
if w < bat[i][1]:
w = bat[i][1]
w_idx = i
elif bat[i][0] == 3 or bat[i][0] == 4:
if l < bat[i][1]:
l = bat[i][1]
l_idx = i
# 가장 긴 각 세로변과 가로변에 붙어있는 가로 세로를 절대값으로 빼면 작은 사각형의 세로와 가로를 구할 수 있음
W = abs(bat[(w_idx-1)%6][1] - bat[(w_idx+1)%6][1])
L = abs(bat[(l_idx-1)%6][1] - bat[(l_idx+1)%6][1]) # %6을 안해주니까 런타임 에러가 났다. 인덱스가 6보다 크면 안되고 어떤 점에서 시작할지 모르기때문에 %6을 넣어야한다
print(((w*l) - (W*L))*n)
n = int(input())
hi = list(map(int, input().split()))
ai = list(map(int, input().split()))
arr = []
total = 0
arr = [[hi[i],ai[i]] for i in range(n)]
arr.sort(key = lambda x:x[1]) # 성장속도가 1에 해당하는 값 기준으로 정렬
for i in range(n):
total += arr[i][0] + arr[i][1] * i
# print(total)
print(total)
a, k = map(int, input().split())
cnt = 0
while True:
if k == a:
print(cnt)
break
else:
if k % 2 == 0 and k >= a*2:
k = k//2
cnt += 1
else:
k -= 1
cnt += 1
(01.16) DFS/BFS 그래프 문제 중 DFS는 감이 잡히기 시작했다..! 실버 3까지는 풀어볼만 한 거 같당
n, k = map(int, input().split())
graph = [int(input()) for _ in range(n)]
a = graph[0]
arrlist = []
for _ in range(n):
arrlist.append(a)
b = graph[a]
arrlist.append(b)
a = graph[b]
if k in arrlist:
print(arrlist.index(k) + 1)
else:
print('-1')
정답코드를 보면서 dfs, bfs 방식이 어떻게 적용되는지 공부했다. dfs는 재귀함수(깊이), bfs는 큐(넓이)를 사용해서 진행된다.
# dfs
n = int(input())
net = int(input())
graph = [[]*n for _ in range(n+1)]
for _ in range(net):
a,b = map(int,input().split())
graph[a].append(b)
graph[b].append(a)
cnt = 0
visited = [0]*(n+1)
def dfs(start):
global cnt
visited[start] = 1
for i in graph[start]:
if visited[i]==0:
dfs(i)
cnt +=1
dfs(1)
print(cnt)
# bfs
n = int(input())
net = int(input())
graph = [[]*n for _ in range(n+1)]
for _ in range(net):
a,b = map(int,input().split())
graph[a].append(b)
graph[b].append(a)
cnt = 0
visited = [0]*(n+1)
def bfs(start):
global cnt
visited[start] = 1
queue = [start]
print(queue)
while queue:
for i in graph[queue.pop()]:
print(queue)
if visited[i]==0:
visited[i]=1
print("visited: %s"%visited)
queue.insert(0,i) # queue 배열 맨앞에 놓기
cnt +=1
bfs(1)
print(cnt)