MLops의 프로세스에는 1. ML 기반의 프로젝트Design 하는 단계, 2. 머신러닝실험하고 개발하는 단계, 3. 모델을 product로배포하고 운영하는 단계가 있습니다. 이때 실험하고 개발하는 단계에 많은 리소스가 소모될 수 있습니다. 예를 들어 주어진 task에 맞춰서 성능을 높이거나, 모바일 기기에 배포가 된다고 하면 하드웨어 성능까지 고려해야 합니다. 이번 글에서는 MLops의 2번째 단계인 머신러닝을 실험에 도움을 주는 Tool에 대해서 살펴볼 예정입니다.
1) 필수 구성 요소
머신러닝을 구축하려면 여러가지 구성요소(configuration)가 필요합니다. 그 중 대표적인 요소에 대해 살펴보겠습니다.
Dataset
머신러닝 모델을 학습 시키기 위한데이터.
Metric
모델의 성능을 측정을 위한평가 지표.
Model
해결하고자 하는 Task의 종류와 Data의 특성에 맞는알고리즘.
Hyper-parameter
모델링 성능을 높이기 위해 사용자가직접 세팅해주는 값.
2) 모델 실험
머신러닝 혹은 딥러닝 모델을 학습할 때, configuration 값을 적절하게 선택해야합니다. 예를 들어 모델의 파라미터를 최적화 시키려면 hyper-parameter를 적절하게 선택해야 합니다. 하지만 처음부터 완벽한 값을 찾기는 어렵습니다. 우리가 원하는 결과를 얻기 위해서는 여러가지 hyper-parameter 값을 변경하며다양한 실험을 해야 합니다.
제 경우에 일일이hyper-parameter를 변경하며 학습 경과를 지켜봤습니다. loss가 수렴이 안되면 learnig_rate를 줄이는 식으로 진행했습니다. 하지만 학습자가 직관적으로 값을 변경하는 경우 다음과 같은 문제점이 발생합니다.
hyper-parameter를 변경하고, 성능을 체크하고, 다른 값으로 바꾸는 과정은매우 비효율적이다.
실험이 많아지고 복잡해지면,기록이 누락되고 방향을 잃을 수 있다.
여러 실험 결과를 비교하기 위해정리하는 과정이 번거롭다.
제가 경험한 문제를 나열했지만, 이 외에도 다양한 문제점이 있을 수 있습니다. 이러한 문제점을 해결하고 효율적인 학습을 할 수 있게 만드는WandB라는 Tool을 소개하고자 합니다.
2. WandB 란?
WandB(Weights & Biases)란 더 나은 모델을 빨리 만들 수 있도록 도와주는 머신러닝 Experiment tracking tool입니다.
(다양한 하이퍼파라미터를 쉽게 모니터링할 수 있는 툴)
1) 주요 기능
Weights & Biases의 Document첫 페이지를 보면 위와 같은 그림으로 W&B를 설명하고 있습니다. W&B Platform은5가지 유용한 도구를 제공하고 있습니다.
W&B Platform
Experiments
머신러닝 모델 실험을 추적하기 위한 Dashboard 제공.
Artifacts
Dataset version 관리와 Model version 관리.
Tables
Data를 loging하여 W&B로 시각화하고 query하는 데 사용.
Sweeps
Hyper-parameter를 자동으로 tuning하여 최적화 함.
Reports
실험을 document로 정리하여 collaborators와 공유.
위에서 정리한 5가지 기능을 통해 여러 사람과 협업하고, 효율적인 프로젝트 관리를 할 수 있습니다. 또한여러 Framework와 결합이 가능해확장성이 뛰어나다는 장점을 가지고 있습니다. 이번 글에서는 Experiments에 대해서 소개드리겠습니다. Experiments 기능은 모델을 학습할 때, 모델 학습 log를 추적하여 Dashboard를 통해 시각화를 해줍니다. 이를 통해서 학습이 잘 되고 있는지 빠르게 파악할 수 있습니다.
2) 가격정책
WandB의 가격은 Basic, Standard, Advanced로 나눌 수 있습니다. 제 경우 개인 프로젝트를 진행하기 때문에 Basic이 무료라는 사실에 더 눈길이 가네요. Basic은 개인 프로젝트 일 경우무제한으로 사용할 수 있고,100GB의 저장 공간을 지원해줍니다! 개인 프로젝트를 무제한으로 실험 할 수 있다니 반갑네요.
3. 사용 방법
1) 회원 가입하기
회원가입의 경우 홈페이지의 메인 화면에서 손쉽게 할 수 있습니다. 노란색 버튼(sign up)을 누르면 다음 화면으로 넘어갑니다.
여기서구글 아이디 혹은 Github 아이디가 있다면 손쉽게 가입할 수 있을 것입니다.
2) project 생성하기
회원가입을 하고 인증 메일에서Confirm my account가 완료 되면, project의 main 화면이 뜹니다.
Create new project를 눌러서 새로운 프로젝트를 생성해봅시다.
저는test-pytorch라는 이름으로 설정하겠습니다.
3. Pytorch Tutorial with WandB
WandB를 이용한 간단한 프로젝트를 진행하면서 설명드리겠습니다. 실습 노트북은 포스트 상단에 있는 링크를 클릭하시면 이동할 수 있습니다.
1) wandb login
import wandb
wandb.login()
우선 wandb를 server와 연결 시키려면 login을 해야되요. wandb.login()을 실행하면 다음과 같은 화면이 나옵니다.
이때 빈칸에API key를 입력해야되요. key는 파란색으로 표시된 링크로 들어가시면 받을 수 있어요. 아래 API key의 화면에서 복붙을 하시면 됩니다.
train 함수에서는 model, loader, criterion, optimizer, config을 매개변수로 받아서 학습을 진행합니다. tqdm을 사용해서 진행 속도를 시각화 했습니다. 그리고 wandb.log() 함수가 loss 그래프를 시각화 할 수 있도록 도와주는 함수입니다. 여기선 epoch을 step으로 받고 avg_loss를 기록하고 있네요.
모든 합수가 정의 됐다면 wandb를 실행시키는 일 만 남았습니다. 위의 함수를 실행 시키면 학습이 진행되면서 wandb에 기록이 됩니다. 그 전에 wandb.init()을 정의해야합니다.
wandb.init() 함수는 wandb web 서버와 연결 시켜주는 기능을 합니다. project name과 wandb id를 적어주시면 됩니다. 그리고 미리 설정된 config 값을 받아서 저장 시켜둡니다.
4. 결론 및 정리
wandb와 watch와 log는 Dashboard에서 실험 log를 시각화하는 역할을 수행합니다. 대표적으로 각 layer에 전파되는 gradients 값을 확인할 수 있습니다. 해당 name은 model의 변수명을 기반으로 작성됩니다. 마우스를 가지고 가면 X축(epoch)에 해당하는 gradient의 단면을 그래프로 확인하실 수 있습니다. 이렇게 학습 기록과 모델의 파라미터를 시각화할 수 있다면 모델 분석을 하기에 매우 유리합니다. Vanishing 문제와 Exploding 문제가 발생하면 즉각 발견할 수 있고 인터넷만 있다면 어디서든 실시간으로 학습 log를 확인할 수 있습니다. 이렇듯 WandB는 머신러닝학습 과정을 추적하고 시각화하여프로젝트 관리에 매우 유용한 Tool입니다. 이러한MLops 패키지를 활용한다면 Kaggle 대회, 개인 프로젝트 등 실험을 할 때 효율적으로 사용될 것입니다.
또한 WandB에는Sweep이라는 hyper-parameter optimization Tool이 존재합니다. 맨 앞에서 언급했던 것 처럼 일일이 사람이 hyper-parameter를 tuning하는 작업은매우 비효율적입니다. 다음 글에서는hyper-parameter란 무엇인지 설명하고Sweep을 다뤄보겠습니다.
를 하면 소문자 알파벳을 순서대로 나열한 리스트가 생성된다. 라이브러리를 알고 있으면 편리하니까 외우도록 하기!!
from string import ascii_lowercase
def solution(s, skip, index):
al_list = list(ascii_lowercase)
answer = []
for i in range(len(skip)):
del al_list[al_list.index(skip[i])]
for i in range(len(s)):
ans = al_list[(al_list.index(s[i])+index) %len(al_list)]
answer.append(ans)
return ''.join(answer)
먼저 컨테이너란, 우리가 구동하려는 애플리케이션을 실행할 수 있는 환경까지 감싸서, 어디서든 쉽게 실행할 수 있도록 해 주는 기술이다.
PC에 프로그램을 설치할 때 특정 경로에 맞춰 설치해야 하거나 내 컴퓨터에 필요한 옵션을 일일히 맞추느라 힘들었을 것이다. 컨테이너는 이러한 환경까지 모두 포함하여 독립적으로 프로그램을 실행할 수 있도록 도와주는 기술이다. 컨테이너 환경을 묵어서 배포한 컨테이너 이미지라는 프로그램을 내려받아 구동하면 실행되서 간편하다.
컨테이너를 쉽게 내려받거나 공유하고 구동할 수 있도록 도와주는 도구로 컨테이너 런타임을 사용한다. 그 중 가장 유명한 것이 도커이다.
쿠버네티스는 컨테이너 런타임을 통해 여러 서버에 컨테이너를 분산해서 배치하거나, 상태 관리 및 컨테이너의 구동환경을 관리해주는 도구이다. 이것을 컨테이너 오케스트레이션이라고 한다.
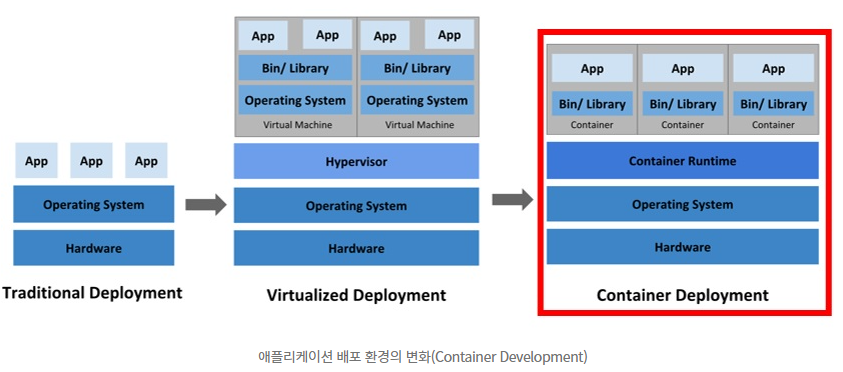
1. Traditional Deployment(전통적 배포):
- 물리적인 컴퓨터 한 대에 하나의 OS를 깔고 여러 가지 프로그램을 설치하는 방식
- PC 한 대에 윈도우를 하나 설치하고, 여러 가지 게임이나 워드프로세서 등을 깔아서 사용하는 것과 비슷한 방식
- 가장 오래되고 단순한 방식
2. Virtualized Deployment(가상화 배포):
- 가상머신(Virtual Machine)을 기반으로 배포를 하는 방법
- 하이퍼바이저: 하나의 시스템 상에서 가상 컴퓨터를 여러 개 구동할 수 있도록 해 주는 중간 계층을 의미
- App: 실행하고자 하는 프로그램, Bin/Library는 프로그램이 실행하는데 필요한 환경과 관련된 파일
- 가상머신은 완전한 컴퓨터이고 가상머신에 일일이 운영체제(OS)를 설치해야 하기 때문에 컨테이너 중심의 배포(Container Deployment)보다는 무거운 편
3. Container Deployment(컨테이너 중심의 배포):
- 컨테이너는 가상머신과 달리 프로그램 구동을 위해서 OS를 매번 설치할 필요가 없음
- OS는 하나만 사용
- 핵심 기술: 같은 OS 상에서 구동되는 프로그램이지만 게임 및 인터넷 프로그램은 서로 다른 컴퓨터에서 깔려있다고 생각하게 함. 즉, 두 프로그램 간에 간섭을 일으킬 수 없음. 이래서 OS에 문제가 일어날 경우, OS에서 구동 중인 전체 컨테이너의 문제가 될 가능성이 있음.