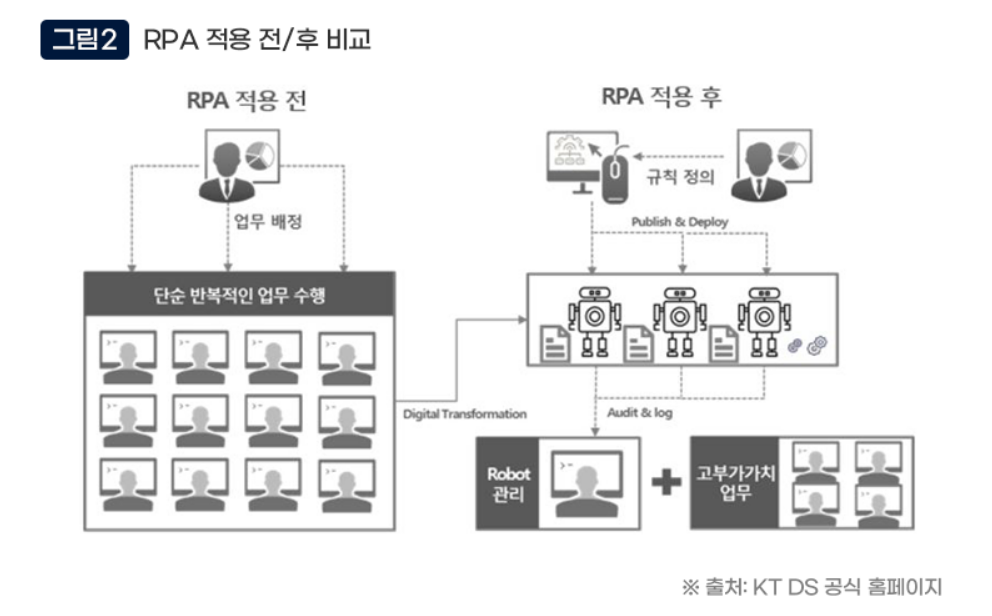
DBMS 무료 툴인 DBeaver은 효율적이고 ssh 적용이 가능하다.
Tool 설치
- https://dbeaver.io/download/
- 환경에 맞는 파일을 다운로드 한다.
- windows installer로 설치
- 설치 안내 마법사: 다음 클릭 -> 사용권 계약 확인: 동의함 클릭 -> 다음클릭 -> 구성 요소 선택: DBeaver Community, include java 선택 후 다음클릭 -> 설치 위치 선택: 다음클릭 -> 설치 클릭 -> 설치 완료
데이터베이스 연결
- PostgreSQL과 연동하기
1. 데이터베이스 클릭 > 새 데이터베이스 연결 클릭

2. 연결하고자하는 DB 클릭

3. 데이터베이스 정보 입력
- Host와 port 입력: postgreSQL이므로 5432
- Database는 작성하지 않아도 됨
- username과 password 입력

4. 연동 완료
'Language & OS > DB' 카테고리의 다른 글
| minio (0) | 2024.02.22 |
|---|---|
| SQL과 NoSQL의 차이 (0) | 2023.01.13 |
| [DB] docker container를 활용해 MongoDB에 데이터 입력하기 (0) | 2022.11.22 |
| [DB] mongoDB 기본 개념 (1) | 2022.11.18 |